The Cost-First AI Stack for Founders in 2026: Why Defaulting to Claude or GPT Quietly Burns Your Margin
There is a default that most founders running AI-augmented businesses have fallen into without quite realizing it: send every task to the best model, treat that as the safe choice, and absorb the cost as a cost of doing business. That default is getting expensive in ways that compound quietly, and the alternatives available in 2026 are better than they have ever been.
Two stories crossed the Hacker News front page in the same week recently that put the numbers in concrete terms. The first was about DeepClaude: a Claude Code agent loop that routes background tasks to DeepSeek V3-0324 while reserving Claude Sonnet for the output layer, achieving comparable quality at roughly one-seventeenth of the cost. The second was Kimi K2.6 outperforming Claude Sonnet and GPT-5.5 on multiple coding benchmarks at a fraction of the price. Together, they illustrate the same point: the premium models are no longer the only models worth using, and the cost difference is no longer marginal.
This is not an argument to abandon Claude or GPT. They are still the right tool for specific tasks. This is an argument for using them where they earn their cost instead of using them as the default path for everything.
What the Cost Differential Actually Looks Like
The pricing gap between frontier models and competitive open-weight alternatives has widened significantly in 2026. The gap is not uniform across model sizes or task types, but for a founder running AI tasks at scale, the numbers are material.
A representative comparison for coding-focused tasks as of early 2026:
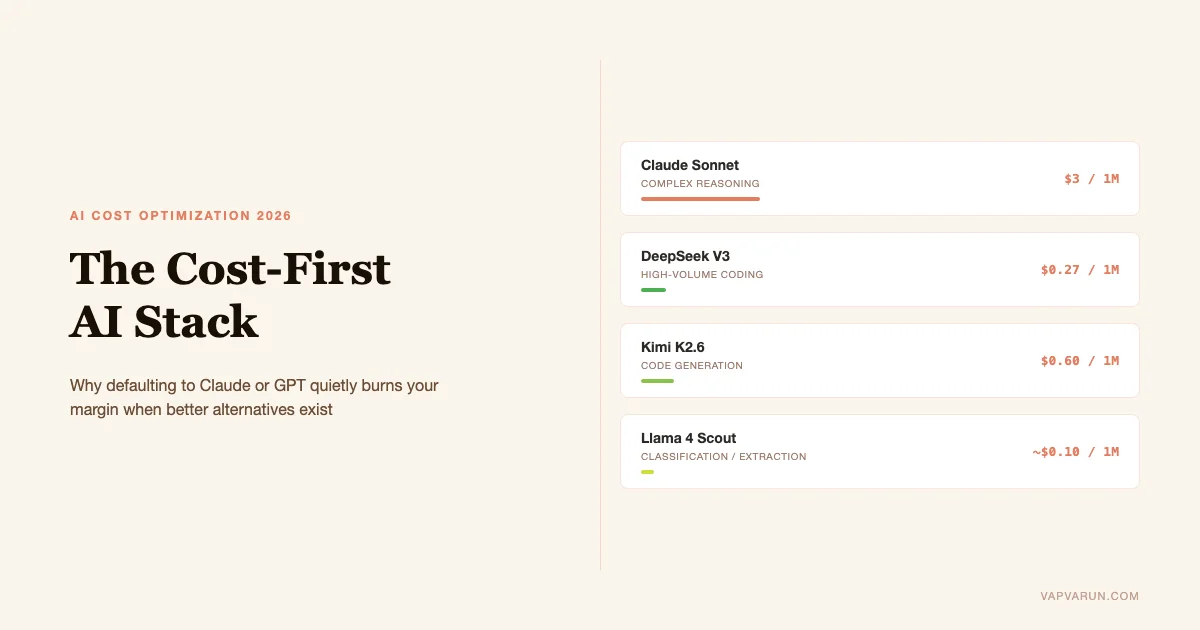
| Model | Cost (input/output per 1M tokens) | Best use case |
|---|---|---|
| Claude Sonnet 4.5 | $3 / $15 | Complex reasoning, nuanced output |
| GPT-4o | $2.50 / $10 | Versatile, multimodal tasks |
| DeepSeek V3-0324 | $0.27 / $1.10 | High-volume coding, data extraction |
| Kimi K2.6 | $0.60 / $2.50 | Code generation, technical writing |
| Llama 4 Scout (hosted or self-hosted) | ~$0.10 / $0.40 | Classification, extraction, summarization |
The cost differential between the top and bottom of this table is 10x to 50x depending on the task. At low volume, that difference is invisible. At the volume that most AI-augmented developer workflows run, it is not.
If a Claude Code session costs you approximately $0.50 in API calls for a mid-complexity task, running that same task through a DeepSeek-first routing strategy might cost $0.03 to $0.05. If you run fifty such tasks per working day, the monthly difference is roughly $700 to $1,100 per developer using the stack. Across a three-person team, that is a meaningful number that does not show up as a line item anywhere obvious until you run the calculation.
Why the Default Sticks
The reason founders stay on premium models even when cheaper alternatives are available is partly habit, partly risk aversion, and partly the absence of clear visibility into what the alternatives actually do for specific tasks. The premium model worked. It was the reasonable default in 2023 and 2024 when the alternatives were genuinely worse. The inertia from that period carries forward even as the landscape has changed.
Risk aversion plays a role too. If a cheaper model produces a subtly worse output in a customer-facing context, the reputational cost can exceed the API savings. That concern is legitimate for some task types. It is not legitimate for all task types, and treating it as a blanket reason to use premium models everywhere is the expensive mistake.
The Case for Mixed Stacks
The DeepClaude architecture described in the HN thread is a useful mental model even if you do not use that specific implementation. The core idea is: use a cheaper workhorse model for the bulk of the processing and reserve the premium model for the steps where its capabilities actually matter.
In a coding workflow, the steps where premium model quality matters most are typically: understanding a complex, ambiguous specification; reasoning about architectural trade-offs; reviewing output for subtle correctness issues that require deep contextual understanding. The steps where cheaper models perform comparably: generating boilerplate from a clear spec, extracting structured data from text, writing tests for a well-defined function, summarizing documentation.
A mixed stack routes tasks by type, not by habit. The habit version routes everything to the same model because that is easy and feels safe. The cost-first version asks, for each task type: what is the minimum capability required here, and which model in my stack provides that capability at the lowest cost?
The Four Swap Rules
Rather than a complex routing matrix, think about this as four practical swap rules for founder-sized teams:
Rule 1: Swap high-volume extraction and classification to cheaper models. If you are running AI on every support ticket, every piece of user feedback, every data row that needs labeling or categorization, you do not need a frontier model. The task is structured enough that a smaller model performs well, and the volume is high enough that the cost difference matters. Route this to Llama 4, Kimi, or DeepSeek.
Rule 2: Swap first-draft generation to cheaper models when the output will be reviewed. If a human is reviewing and editing the output before it is used, the model quality required is lower than if the output goes directly to production or to a customer. First drafts, internal summaries, and content that is one step from the end result are good candidates for a cheaper model. Reserve the premium model for the final refinement step if needed.
Rule 3: Keep complex reasoning and context-heavy tasks on premium models. Multi-turn conversations where the model needs to maintain context across a long session, tasks that require understanding subtle domain-specific constraints, and architectural decisions where the reasoning needs to be correct not just plausible: these are where the capability gap between premium and mid-tier models shows up. Do not try to save money here. The quality difference is real and the cost of a wrong output in these situations is higher than the API cost savings.
Rule 4: Benchmark your actual task types before committing to a swap. Generic benchmarks are a starting point, not a decision. The Kimi K2.6 versus Claude Sonnet comparison on coding benchmarks does not tell you how they compare on your specific codebase with your specific conventions. Spend one day running your real tasks through both models and compare the outputs before routing production traffic to the cheaper option.
The habit routes everything to the best model because it feels safe. The cost-first approach routes by minimum required capability, and the savings compound quickly at scale.

When to Stay on Premium Models
Cost optimization is not a blanket directive to minimize AI spend. There are tasks where the premium models earn their cost clearly, and where saving money on the model is a false economy.
Customer-facing outputs are the first category. If an AI response goes directly to a customer with minimal human review, the quality bar is different from an internal tool. The cost of a mediocre response that erodes customer trust is higher than the API price difference. This does not mean you always need the most expensive model for customer interactions, but it does mean you need to benchmark quality carefully before routing customer-facing tasks to cheaper options.
Complex debugging and root cause analysis are another category. When something has gone wrong in a production system and you need the model to reason carefully about the chain of causation, the capability difference between a frontier model and a cheaper one tends to matter. The debugging session might cost more per call on a premium model, but the time saved from reaching the right answer faster is worth it.
High-stakes specification work is the third category. Writing a specification that an agent will use to execute a multi-step task is a case where quality at the spec layer pays dividends in quality at the execution layer. The spec is the highest-leverage point in an agentic workflow. Saving money on the spec to save money on the execution often ends up costing more in rework than it saved in API calls.
There is also a fourth category worth naming: tasks where you do not yet understand the quality difference. If you have not benchmarked a specific task type on cheaper models, do not assume the cheaper model is adequate. The default in an untested situation should be the premium model while you run the comparison, not the cheaper model while hoping for the best.
The Open-Weights Case
A third category beyond “premium API” and “cheaper API” is worth serious consideration for high-volume tasks with stable specifications: running open-weight models on your own infrastructure. The free AI credit tiers from Together AI, NVIDIA NIM, and Gemini Studio offer a useful bridge for testing open-weight models before committing to self-hosted infrastructure.
The argument for self-hosted open weights in 2026 is different from the argument two years ago. The models are better. Llama 4, Qwen 2.5, and Mistral are competitive with GPT-3.5-class performance across many structured tasks. The hosting cost per token on a good GPU instance is lower than the API cost per token for mid-tier commercial models. And for tasks with clear, predictable input distributions, the self-hosted model can be fine-tuned on your specific domain to outperform a generalist model on that narrow task.
The argument against self-hosted open weights is also different from two years ago. The operational overhead is real and ongoing. Model updates require re-evaluation and re-deployment. The gap between the best open models and the best commercial models has narrowed but still exists for complex reasoning tasks. For a small founder-led team, the infrastructure cost in engineering time may exceed the API cost savings unless the volume is high enough.
The practical threshold: if you are running more than approximately 5 million tokens per day on a single task type with a stable specification, self-hosted open weights are worth a serious evaluation. Below that threshold, the managed API options at the lower price points are typically the better trade-off for a small team.
Practical Implementation: Building a Mixed Stack
The actual implementation of a mixed stack is less complex than it sounds. The core is a routing layer that maps task types to model choices. For most founder teams, this can be as simple as a configuration file that defines which model handles which category of task, with a default fallback to a mid-tier model for anything uncategorized.
The routing decisions to make first are the ones with the highest volume and the clearest task type. If you run a large number of support ticket classifications per day, that is the first task to route to a cheaper model, because the volume is high and the task type is well-defined enough that quality comparison is straightforward. Benchmark it, confirm the quality holds, route it, and move on to the next task type.
The routing decisions to defer are the ones with low volume or ambiguous task types. These are not worth the optimization effort until volume grows or the task type becomes clearer. The time cost of benchmarking and routing a low-volume task does not pay back in API savings for a long time, if ever.
The tooling for managing this in 2026 is mature enough that a basic routing layer does not require custom infrastructure. LiteLLM, for example, provides a unified API interface that supports routing rules across models from different providers. The setup time for a basic mixed stack using existing tooling is measured in hours, not days.
Building the Cost-First Mindset
The practical barrier to adopting a mixed stack is not technical. The routing logic is not complex. The barrier is mostly habits and defaults. The default of “send it to Claude” or “send it to GPT” is a habit formed when the alternatives were meaningfully worse. That habit is now costing money that could stay in margin.
Building the cost-first mindset starts with visibility. Most founders do not have a clear view of their AI API spend broken down by task type. Getting that visibility is the first step. Set up logging that captures model, input token count, output token count, and task type for every AI call in your stack. Look at the breakdown weekly. The tasks that represent the highest volume and the lowest complexity are the candidates for a cheaper routing option.
The second step is building a comparison discipline. Before routing any new task type to a premium model, run it through the two or three cheaper options in your stack for a week on a sample of real inputs. Compare the outputs. If the quality is comparable, use the cheaper model. If the quality is not comparable, use the premium model and document why. The documentation makes future conversations about AI spend easier because you have a record of the reasoning, not just the current habit.
The third step is reviewing the routing decisions quarterly. Model capabilities change fast. A task that required a premium model in Q4 may be well-served by a cheaper model in Q2 of the following year. The cost-first stack is not set-and-forget. It requires periodic re-evaluation as the model landscape shifts.
The Compounding Effect on Margin
The reason this matters more for founders than for large enterprises is margin structure. An enterprise absorbing significant AI API costs across a large team may not feel individual model pricing decisions as meaningful. A founder running a profitable small product or agency feels it immediately in net margin.
At founder scale, AI API costs are often running between 3% and 15% of revenue for AI-heavy workflows. A 60% reduction in those costs through mixed-stack routing is a meaningful net margin improvement that compounds month over month. The money freed up either stays in margin or funds growth without requiring additional revenue to break even on the investment.
The founders who built their stacks in 2023 and 2024, when the alternatives to frontier models were genuinely worse, defaulted to premium models for good reasons. The landscape has changed. The alternatives are better, the price gaps are larger, and the routing tooling to manage a mixed stack is simpler than it used to be. Revisiting those defaults in 2026 is not just cost-cutting: it is bringing your infrastructure decisions in line with the current capability landscape rather than the one that existed two years ago.
The specific numbers will shift as model pricing evolves and new alternatives emerge. The principle will not: every task deserves to be matched to the minimum model capability required to do it well, and the delta between “minimum required” and “premium default” represents margin that is currently being left on the table.
Geography and Currency Neutrality in the Cost Calculation
One nuance worth naming for founders outside North America: the cost impact of AI API pricing is not uniform across geographies in net margin terms, but the relative pricing across models is. Whether your revenue is in rupees, euros, or dollars, the fact that DeepSeek costs one-seventeenth of Claude Sonnet for equivalent tasks is currency-neutral. The savings ratio is the same regardless of what currency your margin is denominated in.
The local impact of the savings is actually larger in markets where revenue is in lower-cost currencies relative to the dollar. A 60% reduction in API costs that represents a meaningful margin improvement for a dollar-denominated founder represents a larger real-terms improvement for a founder operating in a market with a weaker currency, because the API costs are dollar-denominated while the revenue and operating costs are partially local-currency-denominated.
This is worth noting because the discussion of AI cost optimization is often framed around dollar numbers that can feel abstract outside of North American pricing contexts. The underlying principle applies everywhere: route tasks to the minimum capable model, benchmark before routing, review quarterly. The currency in which you measure the savings does not change the logic.
For founders running teams across geographies, it also means that the cost case for mixed stacks is stronger than it might appear when quoted in dollar terms. The API cost savings from optimized routing can represent a genuinely significant improvement in local-currency net margin, depending on how your revenue and cost structure are denominated.
The bottom line for any founder in any market: the premium AI model default costs real money relative to the available alternatives, the alternatives are now good enough for a large category of tasks, and the process of identifying and routing those tasks is bounded and achievable. The work is worth doing. The compounding effect on margin starts the month you do it.
The Two-Sentence Summary
The cost-first AI stack is not a technical architecture. It is a business discipline: match every task to the minimum model capability required to do it well, and review those routing decisions when the model landscape changes. The savings compound. The work to get there is bounded. The default of sending everything to the premium model is a choice, and in 2026, it is an increasingly expensive one.
For founders who want to start this week: pull your last thirty days of AI API invoices, sort by cost, find the three highest-cost line items, and ask whether each one actually needed the premium model or just defaulted to it. The answer to that question is the beginning of the cost-first stack.
The model landscape will continue to improve. The next Kimi K2.6 or DeepSeek breakthrough is not months away; it is weeks. Each improvement widens the gap between what the premium models do and what the cheaper ones can do for routine tasks, and each improvement is an opportunity to revisit routing decisions that were made with an older version of the landscape. The founders who build the habit of periodic review are the ones who will continue to capture those savings rather than leaving them for the next billing cycle to reveal.
The compounding effect is worth stating clearly one more time: if you route 60% of your tasks to cheaper models starting this month, the savings do not just appear once. They appear every month, at the same rate, for as long as you maintain the routing. The cumulative savings over twelve months are twelve times the monthly savings. For a founder running meaningful AI workloads, that cumulative number is significant. It represents real optionality: a hiring decision funded, a marketing experiment funded, a month of runway extended. The cost-first mindset is not about being cheap. It is about recovering margin from an overhead category that grew without deliberate management, and redirecting it toward the things that actually move the business forward.